Diskussion:CAP-Theorem
Meine Anmerkungen
- Das Geldautomatenbeispiel ist tatsächlich falsch und die hinzugefügte Alternative ebenfalls (Trade-Off Entscheidungen sind immer fachlich motiviert). Tatsächlich opfern Geldautomaten im Fall einer Partition die Konsistenz zugunsten der Verfügbarkeit. Der Grund ist extrem einfach: Verfügbarkeit == Gebühren == Umsatz. Anders gesagt: der Schaden durch unzulässige Abbuchungen (kommt extrem selten vor und ist gedeckelt durch das Limit) ist auf Dauer geringer als der von Gebührenverlust (kleiner Betrag, kommt aber häufig vor).
- Der nicht verstandene Punkt: CP- und CA-Systeme sind eigentlich dasselbe. Wenn die Konsistenz oberstes Gebot ist, dann wird im Falle einer Partition auf jeden Fall die Verfügbarkeit (A) geopfert (das System verweigert die Arbeit mit einer Fehlermeldung - täte es das nicht, dann wäre die Konsistenz in Gefahr). Gibt es gerade keine Partition, dann kann die Verfügbarkeit aber immer gewährleistet werden. Ergo: Partition => Verfügbarkeit futsch bei beiden Systemen. Keine Partition => Verfügbarkeit bei beiden Systemen gewährleistet.
- Die Probleme des CAP-Theorems (insbesondere die irrige Annahme man könne nur 2 von 3 Eigenschaften erreichen) hat Brewer (der Erfinder von CAP) hier selbst beschrieben: http://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
Die Annahme es gäbe CA-, CP-, und AP-Systeme ist somit nicht einmal als vereinfachtes Modell zu gebrauchen. Ich würde den Artikel so umschreiben, dass dies eine historische Interpretation des Brewer'schen Theorems ist, die mittlerweile überholt ist und vom Autor auch nicht so intendiert war. Quelle der obige Artikel von Brewer selbst. --ulim, 23:44, 11. Nov. 2012 (CET)
- Finde ich gut. Machst du? Gruß --Flash1984 (Diskussion) 10:26, 12. Nov. 2012 (CET)
Antwort auf Überarbeiten
- Da steht CAP jeweils als graduelle Größe drin. Finde ich von daher jetzt OK.
- Guter Punkt, könnte man einbauen.
- Guter Punkt, könnte man einbauen.
- Ich finde die Erläuterung gut. Ein Hinweis auf NoSQL ist nicht sinnvoll, da NoSQL sehr viele Technologien umfasst und nur einige AP machen. Cloud-Anwendungen können über Event Sourcing auch AP implementieren (und sollten es wohl auch).
- Es ist die Rede von graduellen Größen, finde ich OK.
- Hinweis, dass C aus CAP nicht gleich C aus ACID ist, habe ich eingebaut. Finde ich auch wichtig.
- Den Punkt verstehe ich nicht.
- Bei einem Einzelsystem von hoher Verfügbarkeit zu sprechen, halte ich auch für sinnlos und ich denke auch, dass CAP nur bei verteilten System sinnvoll ist. Ich habe es überarbeitet.
- Ich fand das Beispiel gut, habe es entsprechend der Anmerkung aber modifiziert.
- BASE muss aber erwähnt werden, denke ich.
-- Someone2 (Diskussion) 14:52, 9. Jun. 2012 (CEST)
Überarbeiten
In seiner derzeitigen Form ist der Artikel fast völlig falsch.
- CAP ist eine vereinfachte Darstellung für wesentlich komplexere Trade-offs, man spricht auch von der Asymmetrie des CAP-Theorems, da die Aussage "You can't have C,A and P at the same time, pick two of those" schlicht und ergreifend falsch ist. Falls eine Partitionierung vorliegt, so kann man zwischen C und A wählen (bzw. zwischen gewissen Abstufungen der beiden) - mehr besagt das CAP-Theorem nicht, da man in verteilten Systemen nicht nicht P wählen kann. Falls nun gerade keine Partitionierung vorliegt, so ist ein solches System üblicherweise sowohl konsistent als auch verfügbar - nur im Partitionierungsfall stellt sich überhaupt die Frage. Andernfalls reden wir vom Tradeoff zwischen Konsistenz und Latenz. Üblicherweise äußert sich mangelnde Partitionierungstolerenz in mangelnder Verfügbarkeit.
- Einfache Darstellung von CAP: Mehrere Replika liegen vor, irgendwo gibt es eine Partitionierung. Jetzt kommt ein Update rein. Entweder lehne ich das Update ab (opfere also A) oder ich nehme es an und führe nicht auf allen Replika durch (opfere also C). Wenn keine Partitionierung vorliegt, gibt es keinerlei Grund innerhalb dieses "Dreiecks" auf irgendeine Eigenschaft zu verzichten.
- Der "Beweis" des CAP-Theorems ist auch eher fraglich, wenn man sich dessen Annahmen anschaut. Wir aber üblicherweise so akzeptiert.
- Cloud Computing ist nicht per se "AP", d.h. es wird nicht immer Konsistenz aufgegeben. Korrekterweise müsste man sowieso eher von Cloud Storage oder noch besser NoSQL sprechen - aber die Emanzipation dieser Systeme äußert sich eher darin, dass jeweils unterschiedliche Tradeoffentscheidungen gewählt werden - häufig auch konfigurierbar.
- Es gibt nicht nur schwarz und weiß, C und A sind ein Kontinuum.
- Beispiel AP: In verteilten Systeme spricht man nicht von ACID-Konsisten. Konsistenz meint hier was völlig Anderes und ACID wird üblicherweise eh nicht erreicht.
- CP vs. CA: Wie schon angesprochen, ist das das gleiche in grün.
- Verfügbarkeit und Konsistenz sind bei einem Einzelsystem in der Regel sehr hoch -> das halte ich ja für ein Gerücht. Konsistenz ist leicht möglich, auf einem hohen Level zu halten. Verfügbarkeit...nunja, mal unabhängig von Fehlern ist das Ding spätestens dann nicht mehr verfügbar, wenn die Requestzahl hochgeht.
- Geldautomaten: Das Beispiel ist extrem schlecht gewählt. Gerade ein Geldautomat sollte ja verfügbar sein. Meines Wissens wird das im Regelfall so gehandhabt, dass bei Partitionierung der Verfügungsrahmen herabgesetzt wird. Das würde dann einer Einschränkung von Numerical Error entsprechen [1], ohne die Verfügbarkeit zu sehr zu kompromittieren.
- Der Vergleich zu BASE ist auch müßig. BASE war nur der Versuch, ein genauso griffiges Akronym wie ACID für verteilte Storagesysteme zu finden. Aber ein Vergleich zwischen BASE und ACID ist eher...naja...
- siehe auch [2] als Bsp.
Gruß --Flash1984 (Diskussion) 11:56, 8. Jun. 2012 (CEST)
anschaulichere Grafik
Wäre es nicht sinnvoller, die 3 Buchstaben an die Seiten des Dreiecks zu schreiben, statt an die Ecken? Denn mit den Buchstaben an den Ecken sieht es für mich so aus, als ob man im Extremfall nur auf eines der 3 Ziele optimieren kann (Wenn man sich in einer Ecke befindet). --RokerHRO 08:43, 25. Sep. 2011 (CEST)
Datenbanken-Übersicht
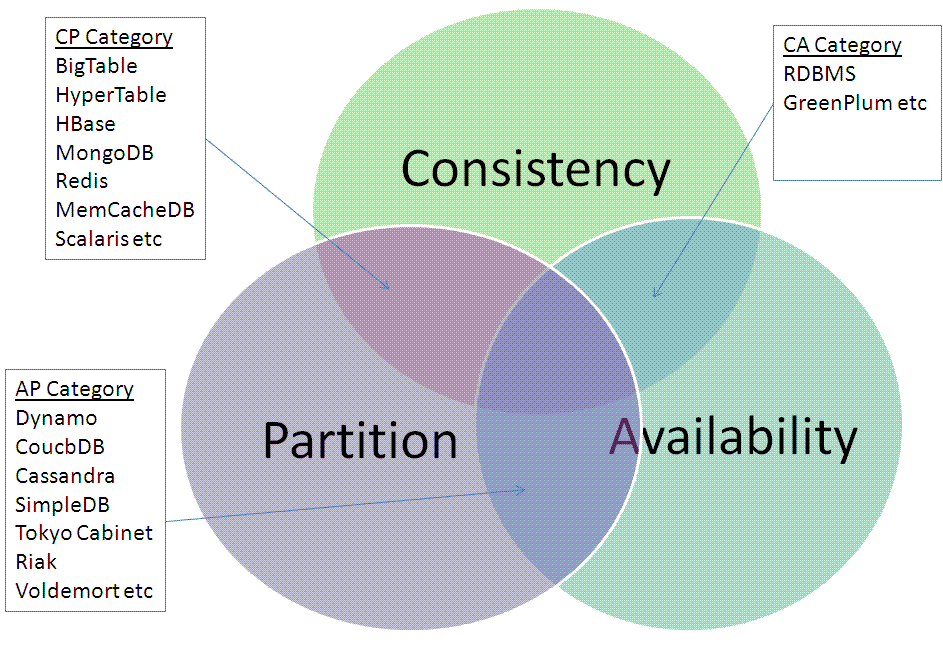
Eine Übersicht, welche Datenbanken an welche Seite des Dreieck gehören wäre toll. So ähnlich wie http://2.bp.blogspot.com/_S1OQqsgO8Vs/S-NwsyqJwPI/AAAAAAAACfU/Lo44suCk_uw/s1600/UPick2-NoSQL.GIF, vielleicht mit einer besseren Aufschlüsselung von RDBMS, damit auch der unbedarfte Leser gleich erkennt, wohin MS SQL Server, MS Access und mySQL fallen... --80.153.118.57 14:23, 16. Jan. 2012 (CET)
Rückfrage zu Überarbeiten
In Nr. 6 bei Überarbeiten heißt es, dass das C ind ACID nicht das gleiche sei, wie in CAP. Allerdings werden ACID-Transaktionen über Knoten einer verteilten Datenbank traditionell mit X/Open XA Zwei-Phasen-Commit sichergestellt. Ist denn bei einem Zwei-Phasen-Commit nicht das C doch das gleiche? (nicht signierter Beitrag von 91.37.216.118 (Diskussion) 19:32, 7. Jan. 2013 (CET))
Es gibt nur zwei Alternativen, nicht drei!
Das CAP-Theorem ist in der ursprünglichen Version ("pick two of three") in der Tat missverständlich formuliert, allerdings nicht grundlegend falsch, wie andere Kommentare suggerieren. Das Problem ist: "P" ist ein Ereignis (Hardware-, Software- oder Netzwerkversagen etc.), "A" und "C" sind Zustände. Die eigentlich korrekte Formulierung des CAP-Theorems ist daher: "Wenn eine Partitionierung auftritt, dann kann man entweder die Fähigkeit für Updates (das ist das A) oder die Konsistenz (das ist das C) retten, aber nicht beides".
Der Normalzustand JEDER verteilten Datenbank ist also AC: Verfügbarkeit und Konsistenz sind gleichermaßen gegeben. Je nach Design der Datenbank, wechselt sie im Falle einer Partitionierung nun in den Zustand AP oder CP: Bei AP sind weiterhin Updates möglich, aber verschiedene Nutzer bekommen nun verschiedene Daten zurück. Bei CP bleiben Updates hängen, dafür sind die nun eingefrorenen Daten weiterhin schön konsistent. --Kai Petzke (Diskussion) 01:08, 22. Aug. 2013 (CEST)
- Stimmt fast, es ist nur eben so, dass sehr, sehr viele verteilte Datenbanken eben selbst im Normalbetrieb aus das C verzichten...Gruß--Flash1984 (Diskussion) 11:56, 22. Aug. 2013 (CEST)
CP-Banking Umgangssprache
Das "so" bei CP-Banking ist eher umgangssprachlich.
"Diese Lösung ist dann jedoch fachlich und hat mit dem CAP-Theorem selber nicht mehr so viel zu tun."
Sehe nur ich das so? (nicht signierter Beitrag von DaTebe (Diskussion | Beiträge) 15:08, 27. Feb. 2015 (CET))

{kind=link}