SpeechRecorder
| SpeechRecorder
| |
|---|---|

| |
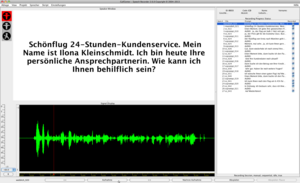 Versuchsleiter-Ansicht in SpeechRecorder | |
| Basisdaten
| |
| Maintainer | Institut für Phonetik und Sprachverarbeitung der Ludwig-Maximilians-Universität München |
| Entwickler | Christoph Draxler, Klaus Jänsch |
| Erscheinungsjahr | 2004 |
| Aktuelle Version | 6.8.0 (03.03.2022) |
| Betriebssystem | Microsoft Windows, Mac OS X, Linux |
| Programmiersprache | Java |
| Kategorie | Audioaufnahme |
| Lizenz | LGPL 3.0 |
| https://www.bas.uni-muenchen.de/Bas/software/speechrecorder/ | |
SpeechRecorder ist eine quelloffene und frei verfügbare Software für skriptgesteuerte Sprach- und Audioaufnahmen. Sie wird hauptsächlich für phonetische, linguistische oder dialektologische Sprachaufnahmen, aber auch zu logopädischen Zwecken oder in der Dysarthrie-Diagnose eingesetzt.
SpeechRecorder präsentiert auf dem Rechner eine Text-, Bild- oder Audiovorgabe und zeichnet das Sprachsignal einer Sprecherin oder eines Sprechers auf. SpeechRecorder unterstützt zwei Sichten auf die Aufnahmen: in der Sprecher-Ansicht zeigt die Software eine Aufnahmesteuerung in Form einer Ampel sowie die zu bearbeitende Vorgabe, die Versuchsleiter-Ansicht umfasst die Sprecher-Ansicht plus eine Liste aller Elemente des aktuellen Skripts, ein Signaldisplay sowie weitere administrative Informationen.
Ein Aufnahmeskript in SpeechRecorder ist ein XML Dokument. Ein Skript ist in Abschnitte untergliedert, die jeweils einzelne Aufnahmen enthalten. Die Abschnitte werden sequentiell präsentiert, die Aufnahmen werden sequentiell oder in zufälliger Reihenfolge abgearbeitet. Jede Aufnahme wird in eine eigene Audiodatei im WAVE-Format geschrieben. SpeechRecorder kann entweder die dem Betriebssystem bekannten Audiokomponenten verwenden, oder die über einen ASIO-Treiber erreichbaren Audiokomponenten. Damit sind Aufnahmen mit zwei oder mehr Kanälen parallel und in hoher Signalqualität möglich.
SpeechRecorder wurde zuerst 2004 auf der Language Resources and Evaluation Conference (LREC) in Lissabon vorgestellt.[1][2] Die Software wurde von Christoph Draxler und Klaus Jänsch am Institut für Phonetik und Sprachverarbeitung[3] der Ludwig-Maximilians-Universität München in Java entwickelt, und steht unter der LGPL 3.0 Lizenz. Die jeweils aktuelle Version ist auf den Seiten des Bayerischen Archivs für Sprachsignale[4] verfügbar.
Mit SpeechRecorder erstellte Aufnahmeskripte können auch im webbasierten Aufnahmetool WikiSpeech[5] verwendet werden. Damit sind verteilte skriptbasierte Sprachaufnahmen über das Internet möglich.
Einzelnachweise
- ↑ Christoph Draxler, Klaus Jänsch: SpeechRecorder -- a Universal Platform Independent Multi-Channel Audio Recording Software. LREC, Lissabon 2004, S. 559–562.
- ↑ Christoph Draxler, Klaus Jänsch: SpeechRecorder - Mehrkanal-Sprachaufnahmen über das WWW. In: Fortschritte der Akustik. 2, (2005), S. 741–742.
- ↑ Webseite des Instituts für Phonetik und Sprachverarbeitung
- ↑ Webseite des Bayerischen Archivs für Sprachsignale
- ↑ https://webapp.phonetik.uni-muenchen.de/wikispeech
