Diskussion:Beurteilung eines binären Klassifikators
SarsCov2 oder Viren mit PCR Test schlecht geeignet
In den Beispielen auf SarsCov2-Test pos/neg zu Krank ja/nein anzuspielen ist genau der gedankliche Fehler, der die "Pandemie" ausgelöst hat, weil man hier etwas übersieht. PCR-Tests sind in-vitro Schlagwortsuche in Oligonukleotiden in einem Abstrich. Die "erste" Wahrheitstabelle muss also lauten: Schlagwort gefunden ja/nein zu SarsCov2 im Abstrich anwesend ja/nein. Und da gilt eben nicht logische Äquivalenz sondern eine Implikation:
Sarscov2 anwesend ==> Test positiv
Es gilt (allgemein) nicht: Test positiv ==> Sarscov2 anwesend
Unter Einhaltung eines einschränkenden Kontextes (in Abstrichen dürfen nur die Oligonukleotide drin sein, die man schon bei der Schlagwortfestlegung kannte) gilt es. Um die Einhaltung des Kontextes kümmert sich aber keiner, da das in freier Wildbahn nicht möglich ist. (nicht signierter Beitrag von 78.43.76.45 (Diskussion) 14:45, 9. Mär. 2021 (CET))
Bsp
| System | Ausgangshypothese | Fehler 1. Art | Fehler 2. Art |
|---|---|---|---|
| Feuermelder | es brennt nicht | Fehlalarm wird ausgelöst | Feuermelder bleibt stumm, obwohl es brennt |
| Gericht | Angeklagter ist unschuldig | ein Unschuldiger wird verurteilt | ein Schuldiger wird freigesprochen |
| Medizinischer Test | Patient ist gesund | positives Ergebnis bei einem Gesunden | vorhandene Krankheit wird nicht erkannt |
| Zugangskontrolle | Person ist zugangsberechtigt | Berechtigter wird nicht eingelassen | Unbefugter erhält Zugang |
Dies Tabelle halte ich in dieser Form für nihct besonders didaktisch und könnte/sollte in das Schema, wie im Artikel, um gegliedert werden. --'~' 18:03, 22. Jan 2004 (CET)
| Angeklagter ist unschuldig | Angeklagter ist schuldig | |
|---|---|---|
| durch ein Gericht fällt eine Entscheindung für:unschuldig | richtige Entscheidung | ein Unschuldiger wird verurteilt |
| durch ein Gericht fällt eine Entscheindung für:schuldig | ein Schuldiger wird freigesprochen | richtige Entscheidung |
ein Anfang:)--'~' 18:28, 22. Jan 2004 (CET)
Ich bin verwirrt. Im Artikel wird einmal "falsch positiv" als Fehler 1. Art bezeichnet, an anderer Stelle als Fehler 2. Art. Was stimmt nun? Leonach 14:52, 8. Mai 2004 (CEST)
- beta (Fehler 2. Art Falsch negativ) und Fehler 1. Art (alpha-Fehler): falsch positiv.--^^~ 15:05, 8. Mai 2004 (CEST)
ich hab http://de.wikipedia.org/wiki/Fehler_1._und_2._Art#medizinischer_Test so umgestellt, dass es dem Schema im Artikel folgt.--^^~ 15:48, 8. Mai 2004 (CEST) Es bliebt die Frage, ob es didaktisch besser ist das
- Spezifität rechts oben ist (folgt dem schema des Artikels)
- oder Selektivität (interessiert die Kranken mehr wenn sie einen medizinischen Test machen)?----^^~ 15:53, 8. Mai 2004 (CEST)
- hab mich fürs schema entschieden.--^^~
Inhalt von falsch Positiv hierher verschoben:
Ein falsch positives Ergebnis liegt vor, wenn ein Test unkorrekt vorgibt, er hätte gefunden, wonach er sucht. Jede Art von Algorithmus, der etwas nachweisen soll, hat eine Tendenz solche Fehlalarme zu produzieren. Ein falsch positives Ergebnis wird auch als Fehler 1. Art bezeichnet.
Ein Beispiel: Eine Krankheit ist selten, der Grundanteil ist 1 von 100. Ein Kranker wird durch einen Test richtig als krank, aber ein Gesunder wird fälschlich auch als krank erkannt. Die Wahrscheinlichkeit für die beiden Personen, dass sie krank sind ist also jeweils 1:1. Darstellung dieses medizinischen Tests mittels eines Entscheidungsbaums:
100
^
/ \
/ \
krank 1 99 gesund
^ ^
/ \ / \
/ \ / \
1 0 1 98
+ - + -
Der falsch positive Test ist hier mit 1 bzeichnet.
Das bedeutet, dass durch den Test 2 von 100 Personen als krank bezeichnet werden, aber einer von beiden gesund ist.
---
habe artikel hierher verschoben, da die meisten leute, die mit statistik zu tun bekommen haben, wohl von fehlern 1./2. art gehoert haben und auch genau nach diesen begriffen und nicht nach klassifikator suchen werden... -- kakau 18:17, 15. Jul 2004 (CEST)
- Dafür gibt es redirects. Der Artikel behandelt nicht nur Fehler 1. und 2. Art, weil das Trennen der verschiedenen Beurteilungskenngrößen in einzelne Artikel unpraktisch wäre. Außerdem gibt es lauter Doppelungen im Artikel -- Nichtich 20:52, 15. Jul 2004 (CEST)
Receiver Operating Characteristic
...wäre ein Artikelwunsch von mir, mfg --^°^ @
- Habe den Beginn gemacht. Müßte nur noch einer das Diagrammbeispiel erzeugen.--Wikipit 23:16, 3. Dez 2005 (CET)
Verwirrend: Statistische Betrachtung
Ich finde den Artikel verwirrend ab Beginn des Abschnitts Statistische Betrachtung.
Stehen dort Bezüge auf Teile, die auf die Diskussionsseite verschoben wurden?
Jedenfalls ist plötzlich von Dingen (Fällen) die Rede, die im Artikel bisher nicht vorkamen.
Ich wollte eigentlich etwas über Fehler der ersten Art lesen, mir bis dato geläufiger als false negative, dazu reichte mit der Text bis dahin, deshalb habe ich auch nicht versucht, den Rest noch zu verstehen, nachdem die Bezüge auf Beispiele, die im Text gar nicht vorkamen, mich "rausgeschmissen" haben.
Nebenbei, die Darstellung der Konfusionsmatrix unter Beispiel erscheint mir auch zur Konfusion des Lesers beizutragen, nachdem dort irgenwelche Kleinbuchstaben in Klammern auftauchen, zu denen es weder vorher noch hinterher eine Erklärung oder Motivation gibt. Gut, man kommt darauf, was gemeint ist, wenn man nur genug darüber nachdenkt - jedenfalls mir ist es gelungen - aber solche antistrukturellen Darstellungen mögen zwar in der wirtschaftswissenschaftlichen Fachliteratur immer wieder vorkommen (-: dienen da aber eigentlich auch nur dazu, das Verständnis zu erschweren, auf daß der nicht-akademische Pöbel nicht so leicht merke, welche Dünnbrettbohrerei dort betrieben wurde :-) jedoch passen sie imho in der Wikipedia nicht so gut, wo ich erwarte, daß ein Artikel auch einem Normalmenschen ein Chance gibt, wenigstens einfachste Sachverhalte auch einfach und schnell erfassen zu können.--Purodha Blissenbach 10:52, 25. Jul 2005 (CEST)
Ich habe diesen Teil erst mal von Duplikaten bereinigt. Aber eigentlich müßte man ihn völlig kürzen. Die beiden polemischen Beispiele habe ich vorne eingebaut. Leider waren die Zahlen der Matrix nicht komplett gegeben. Sollte was falsch sein, bitte ruhig korrigieren. Den ganzen Teil nach der theoretischen Vierfeldertafel kann man sicher löschen!? --Wikipit 21:33, 20. Nov 2005 (CET)
- Der Absatz ist nicht optimal. Letztendlich ist zwar alles korrekt, aber ein Problem der Darstellung ist, dass hier zwei Nullhypothesen existieren, nämlich zum einen die im Text dargestellte und zum anderen Person ist gesund in der medizinischen Untersuchung. Die dargestellten Fehler 1. und 2. Art sind die Fehler der Letzteren und nicht der ersteren, die wieder andere Fehler 1. und 2. Art besitzt - nämlich diejenigen, die aus den statistischen Unsicherheiten der Fehler 1. und 2. Art der medizinischen Testmethode entstehen. Genauer gesagt wäre der zur dargestellten Nullhypothese passende Fehler 1. Art medizinischer Test scheint geeignet, obwohl er es nicht ist und der Fehler 2. Art medizinisches Testergebni scheint zufällig, obwohl es das nicht ist.
- Hier wird also eine Nullhypothese dargestellt, jedoch die Fehler einer anderen Nullhypothese. Das im Rahmen des Lemmas in Ordnung, denn die dargestellte Nullhypothese wird ja anhand dieser Fehler verworfen oder nicht verworfen, nur macht es das für den statistisch nicht fitten Leser dadurch etwas verwirrend. Vor allem, wenn er über die Weiterleitung Fehler 1. und 2. Art hier gelandet ist. Ich habe jetzt auch keine so rechte Vorstellung, wie sich das besser darstellen läßt ohne den Leser zu überfordern. Ich werde allerdings die Weiterleitung Fehler 1. und 2. Art auf Irrtumswahrscheinlichkeit umbiegen, ist dort meines Erachtens besser dargestellt. --Jogy sprich mit mir 08:32, 4. Jun. 2010 (CEST)
Welcher Wissenschaft soll man den Klassifikator zuordnen?
Offenbar hat das Ganze mit Statistik zu tun, jedenfalls alle Beispiele gehören hier hinein? Stochastik als Teil der Statistik wäre auch noch zutreffend? Bedient sich die Klassifikation nur der Statistik oder ist sie ein Bestandteil selbiger. Philosophie, Mengenlehre der Mathematik usw. kämen ja auch noch infrage. Auch fällt mir auf, daß die confusion matrix der Vierfeldertafel gleicht.--Wikipit 12:17, 20. Nov 2005 (CET)
Beispiel Mammographie
Hinkt zu sehr. Autor erkannte selbst, daß hier fehlende Qualität und keineswegs methodische Grenzen zu falsch postiven, schlechten Aussagen führte. Also entfernt!--Wikipit 18:56, 20. Nov 2005 (CET)
Habs erneut rausgenommen, bitte verzeih:
"Wie jeder Test liefert auch die Mammographie falsch positive Testergebnisse. Dies ist der Grund, dass jede zweite Frau, die regelmäßig zu einer (nicht qualitätsgesicherten) Mammographieuntersuchung geht, einen positiven Befund bekommt, obwohl sie gar keinen Brustkrebs hat."
Dieser Satz ist auf einer der Wissenschaft verpflichteten Seite nur deshalb nicht angebracht, weil
...der Zusammenhang von falsch-positiven Befunden und einer nicht qualitätsgesicherten Mammographie nicht wissenschaftlich sondern eher kriminell ist. Mammographien müssen in der BRD qualitätsgesichert nach Standards ablaufen.
...ein "positiver" Mammographiebefund oft nichts über "Brustkrebs" aussagt. Man muß im Vorfeld den potentiellen Patientinnen und den Gesunden eines Screenings sagen, daß jeder Chirurg und Gynäkologe weiss, daß 50% der Damen eine sogenannte Mastopathie haben. Die wird man nur einmal im Leben histologisch sichern wollen. Danach bewertet man bei Mammographien nur neue Veränderungen bzw. hoch sichere Karzinom-Befunde.
...Keine Patientin muss sich einem sie psychisch belastenden Screening unterwerfen. Noch sind wir alle freie Bürger.
...dieser Absatz gar keine gesicherten Zahlen hergibt, die man auch nur annähernd in die Beispiel-Vierfeldertafel zwecks Erläuterung des vorliegenden Artikels einfügen könnte,
...Polemik über unseriöse voreilige Entscheidungen von Berufspolitikern nicht in eine "Enzyklopädie" (=Wikipedia) gehören.
Wer mir antworten will, schreibe auf diese oder meine Diskussionseite... --Wikipit 14:29, 21. Nov 2005 (CET)
Statistik
Den Satz "Diese Parameter sind wichtige Maße in der Statistik und hängen auch von der gewählten Fehlerwahrscheinlichkeit ab (z.B. 68 Prozent für das Zutreffen der Standardabweichung)." habe ich rausgenommen, weil hier Standardabweichung nicht vorkommt usw.--Wikipit 14:46, 27. Nov 2005 (CET) "Klassifizierungsfehler können überall dort auftreten, wo über die richtige Einteilung in zwei Klassen entschieden werden soll." Klassifizierungsfehler können auch bei weniger Klassen als zwei vorkommen.--Wikipit 14:50, 27. Nov 2005 (CET)
Auch ich habe Probleme mit einer normierten Testsituation: "Die Ausgangshypothese (H0, "null" für keinen Unterschied) ist hierbei die Annahme, die Testsituation befinde sich im "Normalzustand", d.h. in den oben genannten Beispielen "es brennt nicht", "der Angeklagte ist unschuldig", "der Patient ist gesund" oder "die Person hat Zugangsberechtigung". Wird also dieser "Normalzustand" nicht erkannt, obwohl er tatsächlich vorliegt, handelt es sich um einen Fehler 1. Art. Beispielsweise wird eine Person zu Unrecht als krank bezeichnet, obwohl sie tatsächlich gesund ist. Falsch Positive (englisch: false positives) sind zu Unrecht als krank bezeichnete Gesunde."
- Aber wie normiere ich einen Test, wenn beide Klassen annähernd gleich häufig sind, z.B. männlich|weiblich ?
- Tests auf Gesundheit gibt es übrigens nicht, nur auf Krankheit
- überwiegende Häufungen von Krankheit gegenüber Gesundheit kann in einer Stichprobe durchaus vorliegen
Formuliere ich aber die Hypothese um, kippt die Matrix bei Beibehaltung von wahr=links oben & rechts unten um die 1.Diagonale. Damit werden Fehler 1. Art zu 2. Art und umgekehrt.--Wikipit 15:22, 27. Nov 2005 (CET)
Habe im theoretischen Beispiel die Nullhypothese umformuliert und danach die Benennung von Fehler 1. und 2. Art notwendigerweise getauscht, weil die Konventionen sagen, daß bei statische Tests die Nullhypothese nur aufgestellt wird, um für die experimentelle oder Alternativhypothese geopfert zu werden. Damit stimmen die Erklärungen am Ende des statistischen Teil wieder gut überein. Nur die Graphen müssen noch nach der Norm vereinheitlicht werden.--Wikipit 20:57, 27. Nov 2005 (CET)
Fehler in der Wahrheitstabelle "Aids in BRD"?
Unter der Tabelle heißt es "Von 119.960 positiven Ergebnissen wären etwa 55% falsch positiv [...]". Müsste es nicht heißen "Von 148.933 positiven Ergebnissen wären etwa 55% falsch positiv [...]"? Das ist die Summe, die in der Tabelle genannt wird. Dann stimmt auch der Prozentsatz. Habe das mal geändert. --80.246.106.4 18:07, 9. Feb. 2011 (CET)
Müsste es im ersten Eintrag nicht statt 40.000 eher 39.960 heißen? Schließlich sind insgesamt nur 39.960 + 40 = 40.000 Einwohner infiziert, nicht 40.000 + 40 = 40.040. Oder liege ich falsch? 84.56.132.193 00:39, 20. Jun. 2007 (CEST)
- Wo Du recht hast, hast Du recht! Hab's im Artikel geändert. --Arno Matthias 02:18, 20. Jun. 2007 (CEST)
- Vielen Dank, Arno! 84.56.134.34 15:19, 20. Jun. 2007 (CEST)
Neue Version des Artikels
Hallo, ich habe auf meiner Benutzerseite eine neue Version des Artikels erstellt, die die vielen Redundanzen der verwandten Artikel (siehe Portal:Mathematik/Qualitätssicherung#Mutter_aller_Redundanzen:_Fehlerklassifikation) auflösen und darüber hinaus die verschiedenen Maße sowie ihr Bezug zur statistischen Testtheorie (bzw. auch die Abgrenzung dazu) besser darstellen soll. Über Feedback zu der neuen Version wäre ich dankbar, wenn keine größeren Bedenken geäußert werden, werde ich ihn den nächsten Tagen die neue Version schrittweise einstellen und die anderen Artikel in Weiterleitungen umgewandeln. Gruss --Darian 22:43, 22. Okt. 2010 (CEST)
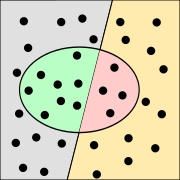
Bildunterschrift
"Die Punkte im Oval sind die von dem Test als krank klassifizierten Menschen." Das sind doch eher sowohl die false-positives bzw. die false-negatives, oder? 194.127.138.16 08:44, 11. Dez. 2010 (CET)
- Nö, stimmt so. Die Farben könnten unterschiedlicher sein, aber sie bedeuten, wie im Abschnitt auch durchgehend verwendet:
- hellrot: falsch negativ (krank, aber vom Test nicht entdeckt)
- hellgrün: richtig negativ (gesund und vom Test auch nicht als krank klassifiziert)
- im Oval:
- dunkelrot: falsch positiv (gesund, aber als krank eingestuft)
- dunkelgrün: richtig positiv (krank und auch vom Test gefunden)
--Arno Matthias 13:12, 11. Dez. 2010 (CET)
- Die Farben sind wirklich nicht sehr glücklich gewählt. --Sigbert 19:17, 11. Dez. 2010 (CET)
- Ich stimme da der ID 194.127.138.16 zu.
- Ich hätte als Farben auch eher Rottöne als kranke und Grüntöne als gesunde Personen verwendet.
- Denn was der Test rausfindet ist meiner Meinung nach nicht so klassifizierend wie die tatsächliche Erkrankung.
- Das würde auch mit derselben Grafik gehen.
- Hellrot: Richtig Positiv: Der Patient ist krank, und der Test hat dies richtig angezeigt.
- Hellgrün: Richtig Negativ: Der Patient ist gesund, und der Test hat dies richtig angezeigt.
- Dunkelrot: Falsch Negativ: Der Patient ist krank, aber der Test hat ihn fälschlicherweise als gesund eingestuft.
- Dunkelgrün: Falsch Positiv: Der Patient ist gesund, aber der Test hat ihn fälschlicherweise als krank eingestuft.
- Dann sind die Personen links der Mitte alle krank und rechts der Mitte alle gesund und im Oval sind die falsch klassifizierten Personen.
-- S Brown 17:59, 6. Aug. 2011 (CEST)
- Fehler gefunden.
- Die Bilder sind genau verkehrt herum beschriften Falsch-positiv ist falsch negativ und sensitivität ist spezifität.Da die bilder schon nicht leicht zu verstehen sind ist soetwas logischerweise nocheinmal :komplett verwirrend und halt schlicht und einfach falsch. ergibt furchtbaren frust beim verstehen probieren.
- sollte ich einen denkfehler haben bitte mich darauf hinweisen, ansonsten ändere ich es im artikel innerhalb der nächsten woche.
--greenlemonsoda (Diskussion) 11:10, 22. Okt. 2013 (CEST)
- Also ich würde sagen, es stimmt wie es im Artikel ist: Die Kranken sind links, und die mit positiven Test sind im Oval, also z. B. falsch-negativ ist links und außerhalb (die Kranken, bei denen der Test negativ ist). -- HilberTraum (Diskussion) 19:32, 22. Okt. 2013 (CEST)
- die nicht gesichtete Version ist richtig. die bilder sind hier richtig beschriftet, jedoch jeder ohne eine wikipedia account sieht die alte fassung und somit die falschen bildunterschriften. man kann sich leicht die unterschiede anschauen indem man sich ausloggt und die seite anschaut. bitte die neue version freischalten!--213.143.119.35 09:36, 13. Nov. 2013 (CET)
Reihenfolge
- Richtig positiv: Der Patient ist krank, und der Test hat dies richtig angezeigt.
- Falsch negativ: Der Patient ist krank, aber der Test hat ihn fälschlicherweise als gesund eingestuft.
- Falsch positiv: Der Patient ist gesund, aber der Test hat ihn fälschlicherweise als krank eingestuft.
- Richtig negativ: Der Patient ist gesund, und der Test hat dies richtig angezeigt.
Halte die Reihenfolge für undidaktisch, würde rp,fn,rn und fp vorschlagen.--^°^ 15:00, 11. Dez. 2010 (CET)
Bild

Das Bild geht von der Abstraktion aus, das Gesund und Krank 50:50 vorliegen, wo soll es da geben? Aidsdurchseuchung in Afrika?-- ^°^ 15:03, 11. Dez. 2010 (CET)
- Wo kommen wir denn da hin, wenn jetzt schon Bilder "von etwas ausgehen"? Es handelt sich bei der Abbildung um ein Venn-Diagramm, das lediglich die logischen Relationen symbolisch darstellt. Die Größen der Flächen symbolisieren gar nix. --Arno Matthias 18:38, 11. Dez. 2010 (CET)
- Nunja, wir kommen zu einer guten Didaktik, das Venn-Diagramm passt mMn. nicht zur Beschreibung (Kranke/Gesunde=i.d.R. Wenige/Viele) oder umkehrt. Wir haben hier die Diskussion "Wikipedia:Laientest vs. einer streng logischen Herführung mit Venn-Diagrammen.--^°^
 zum Vergleich.--^°^ 11:13, 12. Dez. 2010 (CET)
zum Vergleich.--^°^ 11:13, 12. Dez. 2010 (CET)
- Das Bild ist - für das Beispiel und den Spezialfall der relativ seltenen Krankheit sehr gut und anschaulich. Das könnte man an geeigneter Stelle gut einbauen. Die Venn-Diagramme finde ich darum gut, weil sie auch für die Veranschaulichung der einzelnen Maße (Segreganz, Irrtumswahrscheinlichkeit etc.) verwendet werden können. Gruß, -- Darian 00:36, 18. Apr. 2011 (CEST)


Da gefällt mit aber das Bild aus der en WP bessert, hat mMn. mehr Aussagekraft.---^°^ 12:18, 12. Dez. 2010 (CET)
- Das von dir favorisierte Bild geht aber vom Spezialfall aus, dass es viel mehr gesunde als kranke Personen gibt. Klassifikatoren gibt es aber nicht nur in der Medizin, wo solche Verteilungen wohl üblich sind. Im Übrigen besteht im aktuellen Bild keine 50:50 Verteilung, sondern 20:16. Das Bild mit den getesteten Personen hat noch weitere Defizite. Möglich wäre aber, ein Baumdiagram statt eines Venn-Diagram. Die Farbgebung im aktuellen Bild lässt sich auch noch verbessern. -- Nichtich 11:03, 14. Dez. 2010 (CET)
- Das von dir favorisierte Bild geht aber vom Spezialfall aus, welches ist gemeint? "File:Binary-classification-labeled.svg"ist doch nicht so verschieden? Das andere war wirklich nur zum Vergleich. Fein, das ein Baumdiagramm ins Auge gefasst wird.--^°^ 11:59, 15. Dez. 2010 (CET)
Ersuche noch um einen Kommentar oben zur Reihenfolge.--^°^ 12:09, 15. Dez. 2010 (CET)
Aufteilung des Artikels notwendig
Dieser Artikel ist ein Sammelartikel aus sehr vielen eigentlich für sich sehr prägnanten und guten Artikeln, etwa "Irrtumswahrscheinlichkeit". Leider leitet alles auf diesen Sammelartikel. Er ist extrem lang und ermöglicht es dem Leser kaum, eine Information schnell aufzufinden. Dies widerspricht der Schnell-etwas-nachschlagen-Idee einer Enzyklopädie. Ich plädiere dafür, den Artikel in Einzelartikel aufzuteilen, so wie es in Wikipedia üblich ist und diese dann -- dies ist besonders wichtig -- gut miteinander zu vernetzten. Nur so wird man sehr schnell die gesuchte Information finden. 92.231.205.187 09:22, 12. Dez. 2010 (CET)
- Vollkommen richtig, war [1] ursprünglich auch so, voll dafür.--11:16, 12. Dez. 2010 (CET)
- Wir haben die Artikel gerade alle zusammengelegt. Die ganzen Artikel waren seit mehr als einem Jahr in der Diskussion der Qualitätssicherung des Portals Mathematik: Portal:Mathematik/Qualitätssicherung#Mutter_aller_Redundanzen:_Fehlerklassifikation.. Es gab zwei wesentliche Probleme:
- Es fand ein Vermischung fand theoretischen (Fehler 1. Art, 2. Art, Irrtumswahrscheinlichkeit etc). und geschätzten Wahrscheinlichkeiten (Missklassifikationsrate etc.) statt. Speziell wurden Testtheorie und Klassifikationsbeurteilung vermischt.
- Viele der Einzelartikel enthielten auch redundante Informationen.
- Ich würde vorschlagen wir diskutieren hier Portal:Mathematik/Qualitätssicherung#Mutter_aller_Redundanzen:_Fehlerklassifikation. weiter. --Sigbert 12:09, 12. Dez. 2010 (CET)
- Wir haben die Artikel gerade alle zusammengelegt. Die ganzen Artikel waren seit mehr als einem Jahr in der Diskussion der Qualitätssicherung des Portals Mathematik: Portal:Mathematik/Qualitätssicherung#Mutter_aller_Redundanzen:_Fehlerklassifikation.. Es gab zwei wesentliche Probleme:
WP:OMA scheint mir nicht erfüllt, Portal:Mathematik/Qualitätssicherung#Mutter_aller_Redundanzen:_Fehlerklassifikation.ist schont tot, das ging aber flott.--^°^ 10:15, 19. Dez. 2010 (CET)
- Danke für die Blumen, was die Geschwindigkeit angeht :-) Was die WP:OMA-Tauglichkeit angeht: Es war eigentlich mein Ziel, den Artikel trotz der verdichteten Information weiterhin gut lesbar zu halten. Darum würde ich sehr gerne hören, welche Teile du für nicht allgemein verständlich hältst, damit der Artikel weiter verbessert werden kann. -- Darian 00:31, 18. Apr. 2011 (CEST)
Vermutlich Fehler bei Kombinierte Maße
Die Formel F-alpha-score enthält nach anderen Quellen (A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation von Cyril Goutte and Eric Gaussier und engl. wikipedia) ein alpha (bzw. beta) Quadrat in der formel!
also f2 wäre dann mit faktor 4 in der formel und nicht mit 2, wie hier gesagt...
-- SirRichard 134.95.5.14 15:48, 23. Feb. 2011 (CET)
- Auch unter http://en.wikipedia.org/wiki/F1_score und in anderen Quellen, wie in Han, Kamber et al. 2012 – Data mining (S. 369) wird mit beta^2 gewichtet
- --Sailor2040 (Diskussion) 13:06, 13. Feb. 2014 (CET)
Verwirrende Nutzung redundanter Begriffe
Das wesentliche ist schon in der Diskussion uber die Aufteilung gesagt worden, mir ist vor allem die Begriffsnutzung im Abschnitt Kombinierte Maße negativ aufgefallen, aber es zieht sich durch den ganzen Artikel: es werden zwar die Begriffen unter einem Stichpunkt mit ihren verschiedenen Namen vorgestellt, aber dann wird nicht ein einzelner Begriff verwendet, sonderen eine beliebig erscheinende Mischung all dieser Begriffe.
-- Olhor 2012-04-18 (11:19, 18. Apr. 2012 (CEST), Datum/Uhrzeit nachträglich eingefügt, siehe Hilfe:Signatur)
- Hallo Olhor, ich habe deinen Kommentar so verstanden, dass du es vorziehen würdest, wenn jeweils nur der erste Begriff für eines der Maße (also z.B. positive Vorhersagewert und nicht Relevanz) im weiteren Text verwendet würde, richtig? Bei den kombinierten Maßen ist das tatsächlich ein Problem. Ich habe die Angaben damals aus dem Artikel Recall und Precision übernommen, dort wurde natürlich mit diesen englischen Bezeichnungen gearbeitet. Ich werde nochmal recherchieren, welche Begriffe im deutschsprachigen Raum in diesem Zusammenhang üblich sind (oder wenn es sonst jemand weiß - nur zu!). Ansonsten habe ich bei einer kurzen Durchsicht des Artikels nur noch im Abschnitt Information Retrieval abweichende Begriffe gefunden. Das habe ich ja damit begründet, dass diese in diesem Zusammenhang üblich sind. Das erscheint mir wichtiger als maximale Konsistenz, oder was meinst du? Und hast du noch an anderen Stellen des Artikels derartige Probleme gefunden? Gruß, Darian (Diskussion) 11:45, 18. Apr. 2012 (CEST)
Farben
ich muss mich auch nochmal zu den Farben äußern. Mir wird nicht klar warum die Farben in der Tabelle anders sind und warum da gelb und grau auftauchen, die in den Bildern gar nicht vorkommen. Ich finde die hell/dunkel Grün- bzw. Rottöne auch nicht so glücklich, sie sollten zumindest unterschiedlicher sein.95.116.196.123 14:08, 16. Aug. 2012 (CEST)
- Die Farben irritieren mich auch. Zusätzlich zu den unterschiedlichen Grün- und Rottönen sind sie auch inkonsistent mit den Farben in der Tabelle. Dies ist Problem Nr. 1. Ein weiteres Problem ist die Darstellung der Formlen mittels Grafik. Ich kann nicht erkennen, was über dem Bruch und was darunter steht. Dies sollte jedoch aus der Grafik entnehmbar sein. Abgesehen davon wird dann auch ein grau eingeführt, welches in der Tabelle oben mit FN erklärt wird, dies dann aber nicht ist. Mein Vorschlag wäre 1) die Farben der Tabelle zu übernehmen (siehe
 ) und 2) ein kleine Umgestaltung der Grafiken zur Beschreibung der Formel (siehe Datei:Binary-classification-file positive.svg). In der neuen Grafik sind die Elemente, welche über dem Bruch stehen, als hohler Kreis markiert, und alles unter dem Bruch ist durch farbigen Hintergrund repräsentiert. Dies hilf die Elemente der Formel in der Grafik wiederzufinden.MartinGarbe (Diskussion) 10:29, 12. Nov. 2012 (CET)
) und 2) ein kleine Umgestaltung der Grafiken zur Beschreibung der Formel (siehe Datei:Binary-classification-file positive.svg). In der neuen Grafik sind die Elemente, welche über dem Bruch stehen, als hohler Kreis markiert, und alles unter dem Bruch ist durch farbigen Hintergrund repräsentiert. Dies hilf die Elemente der Formel in der Grafik wiederzufinden.MartinGarbe (Diskussion) 10:29, 12. Nov. 2012 (CET)

Anti-Screening Argumentation
Das ist für mich nicht schlüssig. Wenn man die nach Elisa & Western-Blot übrigbleibenden ~150000 Positivfälle einfach alle noch per PCR testet, bleiben vielleicht noch ein paar tausend falsch Positive übrig, plus zehntausend unwissentlich Infizierten. Die bittet man um eine neue Blutprobe, testet erneut, und es sind nur noch ein paar dutzend falsch Positive. Das wiederholt man solange, bis man einfach sicher ist. Da PCR anscheinend nur bei unsauberem Arbeiten falsch positiv meldet (Kontamination mit infiziertem Material), ist man bei drei Blutabnahmen mit unterschiedlichem Personal sicher.
Wenn man deutlich kommuniziert, daß in der ersten Stufe viele fehlerhafte Positive kommen, dann bringt sich doch keiner um!
Es gabe auf einen Schlag fast keine unwissentlich Infizierten im Lande mehr, und damit hoffentlich so gut wie keine Neuinfektionen. Das machen wir nacheinander in allen Staaten Europas, und dann ist es so billig, daß wir es den ärmeren Ländern schenken können. Das AIDS-Problem ist auf Jahre gelöst, und die Pharmahersteller sorgen mit dem Überleben der existierenden Infizierten für ihr eigenes, können also nicht ernsthaft was dagegen haben.
Und ich bin garantiert nicht der erste, der so schlau denken kann, also warum geht das angeblich nicht? --Maxus96 (Diskussion) 01:21, 29. Nov. 2012 (CET)
Es besteht an jeden Bundesbürger (wahrscheinlich auch an nicht-Bundesbürger) das kostenlose Angebot eines anonymen HIV-Tests. Du kannst in einer freiheitlichen Gesellschaft aber niemanden zum Test zwingen.
--91.65.105.13 20:18, 17. Aug. 2013 (CEST)
- Der Abschnitt sollte wirklich überarbeitet werden. Richtig, der Grund, warum in Deutschland kein allgemeines Screening gemacht wird ist das Konzept vom mündigen Patienten. Niemand kann zu einem Test gezwungen werden (von speziellen Ausnahmesituationen abgesehen). Der Grund warum ein allgemeines Screening nicht durchgeführt wird ist also nicht die Sorge vor Suiziden wegen falsch-positiver Ergebnisse. Abgesehen davon, bringt sich bei positiver Diagnose kaum noch jemand (erfolgreich) um, seitdem es eine gut funktionierende Therapie (ART) gibt. In vielen anderen Ländern gibt es den Mechanismus mit dem Abwarten auf den Bestätigungstest nicht. Dort werden positive Ergebnisse teilweise gar per Telefon und ohne weitere unmittelbare Beratung/Betreuung mitgeteilt und es kommt trotzdem nicht zu massenhaften Suiziden. Lange Rede kurzer Sinn: mathematisch mag der Abschnitt zu HIV korrekt sein, aber der Kontext von HIV Screening zu Suizid ist Spekulation und sollte raus. Chakalacka (Diskussion) 03:48, 10. Jul. 2014 (CEST)
- Bei näherer Betrachtung komme ich zu der Überzeugung, dass der Abschnitt zu HIV komplett raus sollte. Es gibt ausreichend andere Beispiele im Artikel, um den Gegenstand des Artikels anschaulich zu erklären. Dafür braucht es kein mathematisch wohl korrektes, jedoch in ihren Auswirkungen (verheerende Welle von Suiziden) rein spekulatives Rechenbeispiel zur HIV-Epidemie. Der tatsächliche Grund, warum es kein allgemeines HIV-Screening der Bevölkerung gibt ist das (in Deutschland garantierte) Selbstbestimmungsrecht des Patienten (siehe auch Entscheidung des Landgerichts Köln, 08.02.1995, 25 O 308/92 bzw. hier). Also, kann der Abschnitt raus? Oder gibt es Freiwillige zur Überarbeitung, um ihn neutral zu gestalten (Anzahl der falsch-positiven Fälle aufrechnen und denen der tatsächlich Infizierten bzw. der falsch-negativen gegenüberstellen usw.) Danke Chakalacka (Diskussion) 04:10, 10. Jul. 2014 (CEST)
- Dieses "Selbstbestimmungsrecht" ist so nirgendwo kodifiziert, bei Pockenimpfung und TB-Untersuchung mußten auch alle mitmachen. Politiker haben nur Angst um ihr Ego, falls ein Versuch so was durchzusetzen an den "liberalen" Bedenkenträgern scheitern würde. Egal, das wird hier zu offtopic. --Maxus96 (Diskussion) 09:59, 12. Jul. 2014 (CEST)
- Ich wollte hier keine allgemeine Diskussion zu dem Thema lostreten, aber es ist relevant für den Artikel. Hier (bzw. in HIV-Test, der hierher verlinkte) wird/wurde behauptet, dass die vielen befürchteten falsch-positiven Ergebnisse der Grund seien warum in Deutschland kein allgemeiner HIV-Screeningtest durchgeführt wird. Siehe diese Textstelle. Und das ist falsch. Was nun das Selbstbestimmungsrecht angeht: Das war ein Urteil des Landgerichts. In diesem Fall bezieht sich das Selbstbestimmungsrecht auf das Recht von einer schweren Krankheit, die man möglicherweise haben könnte nichts zu erfahren, wenn man das nicht möchte. Also mit Impfpflicht hat das nichts zu tun. Chakalacka (Diskussion) 20:16, 12. Jul. 2014 (CEST)
- Dieses "Selbstbestimmungsrecht" ist so nirgendwo kodifiziert, bei Pockenimpfung und TB-Untersuchung mußten auch alle mitmachen. Politiker haben nur Angst um ihr Ego, falls ein Versuch so was durchzusetzen an den "liberalen" Bedenkenträgern scheitern würde. Egal, das wird hier zu offtopic. --Maxus96 (Diskussion) 09:59, 12. Jul. 2014 (CEST)
- Bei näherer Betrachtung komme ich zu der Überzeugung, dass der Abschnitt zu HIV komplett raus sollte. Es gibt ausreichend andere Beispiele im Artikel, um den Gegenstand des Artikels anschaulich zu erklären. Dafür braucht es kein mathematisch wohl korrektes, jedoch in ihren Auswirkungen (verheerende Welle von Suiziden) rein spekulatives Rechenbeispiel zur HIV-Epidemie. Der tatsächliche Grund, warum es kein allgemeines HIV-Screening der Bevölkerung gibt ist das (in Deutschland garantierte) Selbstbestimmungsrecht des Patienten (siehe auch Entscheidung des Landgerichts Köln, 08.02.1995, 25 O 308/92 bzw. hier). Also, kann der Abschnitt raus? Oder gibt es Freiwillige zur Überarbeitung, um ihn neutral zu gestalten (Anzahl der falsch-positiven Fälle aufrechnen und denen der tatsächlich Infizierten bzw. der falsch-negativen gegenüberstellen usw.) Danke Chakalacka (Diskussion) 04:10, 10. Jul. 2014 (CEST)
Kombinierte Sensitivität und Spezifität
Im Beispiel AIDS wird folgendes behauptet: "Bei positivem ELISA-Suchtest wird ein Western-Blot-Bestätigungstest durchgeführt, so dass kombiniert eine Sensitivität von 0,999 und eine Spezifität von 0,999996 erreicht wird." Die kombinierte Spezifität sollte, wie dargelegt, steigen. Da beide Tests jedoch positiv ausfallen müssen, damit jemand als positiv eingestuft wird, sinkt die kombinierte Sensitivität. Die Tests haben jetzt ein kombiniertes Risiko falsch negativ zu sein.
Bsp.: 10000 positive Patienten, Test A und B haben eine Sensitivität von 90.0%
Test A detektiert 9000 -> 1000 falsch negativ Test B detektiert nochmal 8100 der durch Test A Pos. getesteten Patienten -> 900 falsch negativ. Wenn A und B positiv sein müssen, folgt: 1000 + 900 = 1900 falsch negative. Damit ergibt sich eine kombinierte Sensitivität von (10000-1900)/10000=0.81 ->81%
Wenn ich das richtig sehe, sollte also im Falle eines sequentiellen Tests, bei dem beide Tests positiv ausfallen müssen, bei einer Sensitivität von 0.999 eine kombinierte Sensitivität von 0.999^2=0.998 vorliegen.
--91.65.105.13 20:13, 17. Aug. 2013 (CEST)
Orthographie
In der Wörtern Falsch-negativ-Rate und Falsch-positiv-Rate müssen die mittleren Wörter positiv und negativ am Anfang klein geschrieben werden, weil es keine Hauptwörter sind. --Dr. Hartwig Raeder (Diskussion) 13:07, 12. Mär. 2014 (CET)
- Wieso hast du das nicht selbst umgesetzt? -- Nescimus (Diskussion) 20:11, 26. Jan. 2017 (CET)
prägnante Darstellung
Hier ein eingängiger Arktikel dazu. Mittels eines Schaubilds ist das Thema auf einem Blick veranschaulicht. Wie kann man sowas einfügen?--Heebi (Diskussion) 09:32, 9. Sep. 2016 (CEST)
- Hallo Heebi, direkt einfügen kannst du das Schaubild nicht, da es mit Sicherheit urheberrechtlich geschützt ist. Du kannst aber ohne Weiteres die Zahlenwerte nehmen, um ein eigenes Schaubild zu erstellen und es dann unter einer freien Lizenz hochladen und in den Artikel einbinden. Wie das geht, wird hier beschrieben: Hilfe:Bildertutorial. Meld dich gerne, wenn du noch Hilfe brauchst. Viele Grüße, Darian (Diskussion) 12:11, 9. Sep. 2016 (CEST)
Allgemeinverständlichkeit
Hallo zusammen, ich habe ein Problem mit der Allgemeinverständlichkeit dieses Artikels. Das beginnt schon beim Titel „Beurteilung eines binären Klassifikators“ (wenn man ihn unter diesem Titel überhaupt findet). Wenn man den Artikel der Reihe nach durchliest, scheitert wohl fast jeder Laie an der Einleitung von „Statistische Gütekriterien der Klassifikation“, bevor er/sie z.B. zur Sensitivität vordringt, was denn wieder einigermaßen verständlich erklärt ist.
Ich halte dieses Thema für zu wichtig, um es "den Mathematikern zu überlassen". Gerade im medizinischen Bereich betrifft das viele patientennahe Test, wenn nicht gar zur Eigenanwendung (z.B. Schwangerschaftstest). Hier kommt es oft zu Missverständnissen und sogar viele Fachleute sind offenbar nicht immer sicher.
Was kann man machen? Eine allgemeinverständliche Zusammenfassung am Anfang? Ein eigener Artikel zu qualitativen medizinischen Tests? (sorry, wenn die Vorschläge doof sind, ich bin noch relativ neu hier) --XoMEoX (Diskussion) 20:09, 2. Dez. 2017 (CET)
- +1! Vielleicht im ersten Satz schon unterbringen "die Beurteilung eines binären Klassifikators ist ein häufiges Problem, etwa bei medizinischen Tests. Es meint..." - ich schwanke da auch, ob Dein 2. Vorschlag sinnvoller ist...--Mager (Diskussion) 13:52, 3. Dez. 2017 (CET)
- Vielen Dank für Dein Feedback. Ich habe mal auf meiner Spielwiese ein groben Entwurf gemacht, wie ich mir das vorstelle --XoMEoX (Diskussion) 16:23, 3. Dez. 2017 (CET)
- Ich stimme der Zielsetzung völlig zu, halte einen eigenen Artikel aber für den falschen Weg. Ein solcher Artikel wäre zur mathematischen Behandlung identisch, mit dem einzigen Unterschied, dass konkrete medizinische Bezeichnungen verwendet würden. Ich würde stattdessen vorschlagen, in diesem Artikel früh konkrete Bezeichnung (wie krank und gesund) zu verwenden, mit dem Hinweis versehen, dass es sich für andere Klassifikationen (Feuer/kein Feuer usw.) natürlich analog verhält. Mathematische Betrachtungen, die zum Verständnis der meisten Leser nichts beitragen, können in Abschnitte am Ende des Artikels ausgelagert werden; Wikipedia ist zuallererst ein Nachschlagewerk für die Allgemeinheit und kein Fachbuch. Vorschläge für einen attraktiveren Titel? -- Nescimus (Diskussion) 22:52, 3. Dez. 2017 (CET)
- "Beurteilung eines qualitativen Tests"? Ist das dann bei Feuermeldern und dergleichen auch richtig? Ich habe mal den ersten Teil entsprechend Deines Vorschlags grob umgearbeitet. Ich schlage folgende Änderungen vor:
- Klassifikator -> Test
- Korrekt klassifiziert -> richtiges Ergebnis
- Wahrscheinlichkeiten habe ich rausgenommen und statt dessen in den Formeln die Kenngröße genannt ("Sensitivität =...").
- Einige nach meiner Ansicht nicht allgemeinverstädliche Passagen habe ich rausgenommen, soweit sie für das Verständnis erst mal nicht notwendig sind. Darauf kann man dann weiter unten eingehen.
- Kann jemand beurteilen, ob das auch für die anderen Fälle passen würde? --XoMEoX (Diskussion) 09:14, 9. Dez. 2017 (CET)
- Bei "qualitativer Test" könnte man dir WP:Begriffsfindung vorwerfen, denn man findet über Google kaum wirklich passende Einträge dazu. Insbesondere scheint mir die Terminologie in Abgrenzung zum quantitativen Test (den man in anderen Bereichen wahrscheinlich schlicht als Messung bezeichnen würde) recht medizinspezifisch zu sein. Wir sollten auch nicht in Widerspruch zum mathematischen Testbegriff geraten, wobei ich nicht beurteilen kann, ob das hier gegeben ist. Sprachlich finde ich es unglücklich, von "tatsächlich positiv" zu sprechen, denn wer positiv getestet ist, ist doch tatsächlich und nicht etwa nur scheinbar positiv getestet. -- Nescimus (Diskussion) 10:16, 13. Dez. 2017 (CET)
- "Beurteilung eines qualitativen Tests"? Ist das dann bei Feuermeldern und dergleichen auch richtig? Ich habe mal den ersten Teil entsprechend Deines Vorschlags grob umgearbeitet. Ich schlage folgende Änderungen vor:
- Ich stimme der Zielsetzung völlig zu, halte einen eigenen Artikel aber für den falschen Weg. Ein solcher Artikel wäre zur mathematischen Behandlung identisch, mit dem einzigen Unterschied, dass konkrete medizinische Bezeichnungen verwendet würden. Ich würde stattdessen vorschlagen, in diesem Artikel früh konkrete Bezeichnung (wie krank und gesund) zu verwenden, mit dem Hinweis versehen, dass es sich für andere Klassifikationen (Feuer/kein Feuer usw.) natürlich analog verhält. Mathematische Betrachtungen, die zum Verständnis der meisten Leser nichts beitragen, können in Abschnitte am Ende des Artikels ausgelagert werden; Wikipedia ist zuallererst ein Nachschlagewerk für die Allgemeinheit und kein Fachbuch. Vorschläge für einen attraktiveren Titel? -- Nescimus (Diskussion) 22:52, 3. Dez. 2017 (CET)
- Vielen Dank für Dein Feedback. Ich habe mal auf meiner Spielwiese ein groben Entwurf gemacht, wie ich mir das vorstelle --XoMEoX (Diskussion) 16:23, 3. Dez. 2017 (CET)
Medizinischer Bezug im HIV Beispiel und falsche Anwendung von Bayes-Statistik
M.E. kann man das HIV Beispiel so nicht bringen. Im Kern ist es falsch.
Zunächst einmal fehlt der Hinweis, dass es sich um ein medizinisches Thema handelt. Personen, die HIV positiv getestet worden sind könnten das lesen und falsche Schlüsse ziehen. Die in der Realität beobachteten Spezifitäten sind deutlich geringer: http://jlpm.amegroups.com/article/view/3719.
Man darf auch nicht vergessen, dass es sich bei den angegebenen Spezifitäten häufig um Angaben des Herstellers handelt. Oder aber um Angaben eines Krankenhauses oder Labors, dass sich entsprechend kompetent in der Diagnose darstellen möchte.
Dazu kommt, dass es sich um eine rein mathematische Betrachtung handelt, die eine falsche Modellierung beeinhaltet. Das betrifft die Anwendbarkeit der Bayes Statistik. In der Praxis gibt es auch recht häufig das Testresultat "unbestimmt". Das hängt mit der Art und Weise zusammen, wie die Banden im Western Blot Test interpretiert werden. Das ist nicht einheitlich geregelt, siehe: http://docdro.id/AWNfVdq
Die Vorausetzung für die Anwendung des Satz von Bayes zu den a-priori Wahrscheinlichkeiten für den 2. Schritt ist damit nicht gegeben, da es 3 Zustände gibt und nicht 2. Hinzu kommt auch, dass die Interpretation der Banden (siehe oben) anhand der mutmaßlichen Risikogruppe erfolgt. D.h. das Ergebnis wird vom diagnostizierenden Arzt in der Analyse mit eingerechnet. (http://www.who.int/hiv/pub/guidelines/india_art.pdf, Seite 86). Dies geschieht allein schon deshalb, da in Risikogruppen häufig weitere Viruserkrankungen anzutreffen sind, die zu Falschen-Positiven beim HIV Test führen.
Es gibt systematische Fehler, die in dieser Betrachtung fehlen, die jedoch erheblichen Einfluß haben können: Kreuzreaktionen nach Impfungen, Schwangerschaft oder Dialyse. Oder eine Hepatitis Vorbelastung die ebenfalls kreuzsensitiv reagieren kann. https://www.ncbi.nlm.nih.gov/pubmed/25051080 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4700595/ https://www.ncbi.nlm.nih.gov/pubmed/1349089
Dies führt systematisch zu Falschen-Positiven (siehe oben: medizinischer Hinweis)
Ein weiterer systematischer Fehler stammt aus der Abhängigkeit von ELISA und Western Blot wg., die auf dieselben Antikörper testen, beim Western Blot test sind die Proteine zusätzlich nach Gewicht getrennt (Banden). http://www.fb06.fh-muenchen.de/fb/index.php/download.html?f_id=6075.
D.h. die Tests sind gerade nicht unabhängig, so das die Verwendung der ELISA Resultate als a-priori Wahrscheinlichkeit wiederum systematisch verfälscht werden kann.
Daran ändert auch der Hinweis auf 3rd, 4th oder 5th Generation HIV Test nichts. Im Kern geht es immer um dieselbe Antigen / Antikörper Reaktion.--JohKran (Diskussion) 11:47, 6. Jan. 2018 (CET)
Zweifelhafte bis falsche Schlußweise in Quelle Kleinman et al: False-Positive HIV-1 Test Results...
Zu Kleinman et al: False-Positive HIV-1 Test Results in a Low-Risk Screening Setting of Voluntary Blood Donation.
Die Angaben der Quelle zum HIV Beispiel, die eine Spezifität von des Western Blot Test von 0,999.996 gefunden haben wollen, ist nicht zulässig. Das steht zwar im Abstract ist aber im Text nicht substantiiert.
Das Vorgehen suggeriert hohe Spezifitäten, indem durch große Grundgesamtheiten (hier mutmaßlich 5,02 Mio.) dividiert wird. Tatsächlich untersucht wurden in dieser Studie 421 Proben.
Die Quelle schreibt im Abstract, dass in einer Studie zu Falschen-Positiven HIV-1 Tests 5 Mio. Blutspender untersucht worden sein. Das ist nicht richtig. Im Text wird dann ausgeführt, dass aus einer Datenbank, die Daten zu 5,02 Mio Blutspendern enthalten hat, nach nicht näher spezifizierten Kriterien 4650 Proben ausgewählt worden sind ("repeat-reactive") und davon (?) seien 421 HIV-1 Western Blot positiv gewesen. Von diesen 421 Proben zeigten 39 Proben kein p31 Band. Diese 39 Proben wurden weiter untersucht, und zwar nach dem PCR Verfahren.
Nach dem PCR Verfahren wurden von den 39 Proben 20 als Falsche-Positive identifiziert. Dividiert man nun diese 20 durch die 5.020.000 Blutsprender, so errechnet der Artikel ein Vorkommen von 0,0004% Falschen-Positiven in der Grundgesamtheit der Blutspender (= 1 zu 251.000 Falsche-Positive), S. 1083. In Differenz zu 100% wird damit die Spezifität des Test zu 0,999.996 berechnet.
Gänzlich ausseracht gelassen wurde die Frage nach dem Testergebnis "unbestimmt".
Diese Schlußweise ist nicht zulässig, da durch die Auswahl der 4650 Proben (EIA) bzw. der 421 Proben (Western Blot) die Grundgesamtheit schon eingeschränkt wurde und vollkommen unklar ist, wie diese Auswahl zustande kam. Ein Rückrechnen auf die 5,02 Mio. ist damit nicht mehr möglich. Hätte man die Proben anders und in anderer Zahl ausgewählt, wäre das Ergebnis ein anderes.
Der Artikel könnte als Quelle zum HIV-1 Western Blot bzw. zum PCR Test nützlich sein. In Tabelle 2 ist gezeigt, wie schwierig die Interpretation der Bänder im Western Blot Tests ist. Zudem ist festgehalten, dass 2 von 38 Proben ein Falsches-Positive im PCR Test gezeigt haben, was die Autoren als vergleichbar mit einer anderen Studie bezeichnen (5% Falsche-Positive bei PCR).
Als Quelle für eine angebliche Spezifität von 0,999.996 taugt der Artikel aus den genannten Gründen nicht.--JohKran (Diskussion) 11:47, 6. Jan. 2018 (CET)
2x2-Tabelle
MMn ist es üblicher die Tabelle so zu gestalten dass die Totale im Rand erscheinen:
Person ist krank Person ist gesund Totale Test positiv richtig positiv
(rp)falsch positiv
(fp)rp+fp Test negativ falsch negativ
(fn)richtig negativ
(rn)fn+rn Totale rp+fn fp+rn rp+fn+fp+rn
Dabei ist es gut die Unterschied zu beachten zwischen die Population auf der sich die Situation bezieht, und die Stichprobe deren Ergebnissen zu Schätzungen führen der Parametern der Population. Madyno (Diskussion) 22:45, 27. Nov. 2018 (CET)
Der beste Test
... ist doch der mit einer Sensitivität von 100 % und einer Spezifität von 100 % ?--Walmei (Diskussion) 16:43, 24. Jul. 2020 (CEST)
Verwirrung bei Sensitivität und Spezifität zwischen dem Wahrscheinlichkeitsbegriff und der Realisierung
In dem Abschnitt wird nicht ausreichend klar getrennt zwischen Sensitivität (Spezifität) in Form einer aus einem Normierungsversuch geschätzen Wahrscheinlichkeit von z.B. p=0.98 und der Realisierung bei der Anwendung eines Test wie einem PCR-Test zu SARS-CoV-2. Erstere ist in der Tat eine Verallgemeinerung aus einem Versuch auf die Gesamtheit der Merkmalträger (Nichtträger), letztere aber nur auf die getesteten Merkmalträger (Nichtträger).
Es scheint mir am besten, wenn man die Begriffe mit Bezug auf den Wahrscheinlichkeitsbegriff formuliert und auf ein Beispiel mit einer Testgruppe verzichtet, das auf die Realisierung dieser Wahrscheinlichkeit beruht. Henze schreibt z.B. in "Stochastik für Einsteiger": "Unter Sensibilität versteht man die Wahrscheinlichkeit p_se, mit der eine kranke Person als krank erkannt wird."
D.h. in keinem Fall, dass von 100 Infizierten bei P=0.98 98 ein positives Testergebnis erhalten, sondern dass jeder der 100 eine 98%-ige Wahrscheinlichkeit hat, ein ein positives Testergebnis zu erhalten.
Der Abschnitt passt nicht:
"Beispielsweise entspricht Sensitivität bei einer medizinischen Diagnose dem Anteil an tatsächlich Kranken, bei denen die Krankheit auch erkannt wurde. Die Sensitivität eines Test gibt an, wie viel Prozent aller Infizierten auch tatsächlich erkannt werden. Beispielsweise bedeutet eine Sensitivität eines Tests auf COVID-19 von 98 %, dass 98 % der Infizierten erkannt und 2 % der Infizierten nicht erkannt werden. 2 % (der Infizierten, welche getestet wurden und nicht aller Getesteten) wären dann also falsch negativ."
Der erste Satz, "Beispielsweise entspricht Sensitivität bei einer medizinischen Diagnose dem Anteil an tatsächlich Kranken, bei denen die Krankheit auch erkannt wurde", wäre richtig, sofern er beschriebe, wie die Sensitivität für einen Test geschätzt wird. Besser wäre in etwa: "Beispielsweise schätzt man die Sensitivität einer medizinischen Diagnose durch den Anteil an tatsächlich Kranken, bei denen die Krankheit auch erkannt wurde."
Der zweite Satz ist insgesamt falsch: Das Erkennen einer Infektion setzt eine Diagnose voraus. Wird eine Person nicht getestet, kann ihre Infektion nicht erkannt werden (vgl. meine Anmerkung zu meiner ebenfalls missglückten Version in Bezug zur Dunkelziffer).
Der dritte Satz ist Ausdruck eines missverstandenen Wahrscheinlichkeitsbegriffs (abgesehen davon muss es SARS-CoV-2 heißen, nicht COVID-19).
Zusätzlich wäre hier evtl. auch hilfreich, wenn zwischen "theoretischer Sensitivität" (geschätzt durch das den Test entwickelnde Labor) und "praktischer Sensitivität" (geschätzt durch das anwendende Labor) unterschieden würde. (nicht signierter Beitrag von JoernHahn (Diskussion | Beiträge) 19:01, 6. Nov. 2020 (CET))

{kind=link}